Description
- Map Reduce Scripts are used to run a script either on a schedule or when manually triggered.
- Map/reduce scripts have multiple entry points as we’ll see below.
- Map/reduce scripts, as the name implies, run a script on an input array that you provide in one of the entry points.
Why Map Reduce?
- You might hit the script usage limit.
- Map/reduce scripts can run processes in parallel for elements in the array resulting in a faster execution time.
Life cycle of MR Script
Four entry points are defined in a map/reduce script:
getInputDatamapreducesummarize
The general life cycle of a map/reduce script is:
getInputDatais called. Do whatever logic you need – saved search, suitelet, etc. – and return the input data.mapis called for each key/value pair in the input data. This stage should be used to transform the keys to group them to be used in the reduce stage.shuffleis called. This is not an entry point and is not defined in the script. NetSuite will group key/value pairs if the keys match from the pairs returned by the map stage.reduceis called for each of the key/value pairs. This is where you perform the logic that you need to on each key/value pair. This is where you can use write data to be used in the summarize function.summarizeis called. This is where you can use data from the reduce function if you have some cleanup or final tasks to do. This is only called once.
Of these entry points, only getInputData is strictly required. Only define summarize if you need to do some final cleanup or processing of the data. Between map and reduce one of them must be defined.
Nevertheless I recommend always defining the reduce function and using the map function as needed.
Let’s take a look at when you might need the map stage.
When to Use the Map Stage
To understand the map and reduce stages, let’s imagine I have 4 work orders for 2 customers:
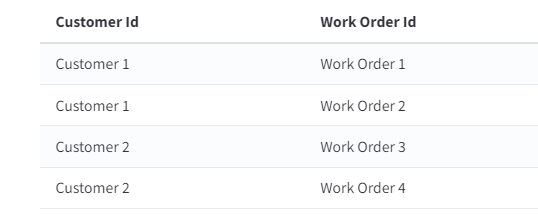
There’s two ways I might want to process this data. Either I want to process each work order separately or I might want to process all of the work orders for customer 1 together and all of the work orders for customer 2 together.
If I want to process each work order separately, I can omit the map stage and just return the work order ids in the getInputData function. In the reduce stage I can process each work order individually.
It is possible to use the map stage to process each work order individually, but because the reduce stage is needed if you want to write data to be used in the summarize stage or if you want to group the data, I recommend always using the reduce stage.
What if I want to process all of the work orders for customer 1 together and all of the work orders for customer 2 together? Then I will need to use the map stage to transform the keys somehow so that NetSuite will group them together when it calls the reduce stage.
When I call getInputData I will have it return an array that just contains the work order ids.
const getInputData = (inputContext) => {
return [
'Work Order 1',
'Work Order 2',
'Work Order 3',
'Work Order 4',
]
}
Now after the map stage, before the reduce stage, NetSuite will group the work orders by customer id.
There are the four values returned by the map stage:
[
{ 'Customer 1': 'Work Order 1' },
{ 'Customer 1': 'Work Order 2' },
{ 'Customer 2': 'Work Order 3' },
{ 'Customer 2': 'Work Order 4' },
]
NetSuite will group the values by their keys, in this case the customer id:
[
{ 'Customer 1': [ 'Work Order 1', 'Work Order 2'] },
{ 'Customer 2': [ 'Work Order 3', 'Work Order 4'] },
]
Now NetSuite will pass each group of work orders separately in the reduce stage.